 To download the program, click
here and look for "FreqAnalysis" under the heading
"Xtras". Visual Basic 6 source code is provided.
Requires the VB6 runtime (not included, try getting it here).
To download the program, click
here and look for "FreqAnalysis" under the heading
"Xtras". Visual Basic 6 source code is provided.
Requires the VB6 runtime (not included, try getting it here).To download the program, click
here and look for "FreqAnalysis" under the heading
"Xtras". Visual Basic 6 source code is provided.
Requires the VB6 runtime (not included, try getting it here).
I wanted to design a keyboard layout for MilliKeys that would take into account both
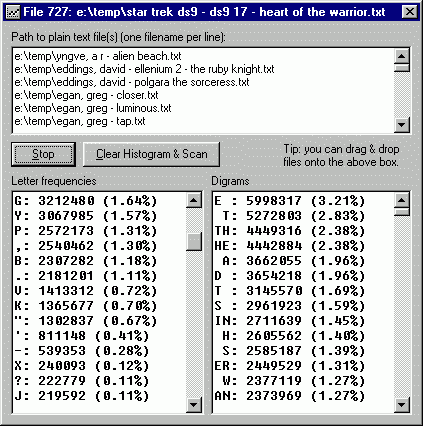
Unfortunately I couldn't find this information on the web in a useful format. In particular, I have never seen any comparisons between the frequencies of digrams and the frequencies of individual letters. It's nice to know that "th", "he", and "e " are very common digrams, but how common is "th" compared to "e", for instance? This program tells me.
So, I made a program to do it for me. I Intended to share this little proggie with the world, so it's got a clean user interface, and I fixed bugs that didn't need fixing (for example, it used to fail to count the last character in the last file...big whoop.) There might be a bug or two in the drag-and-drop code, however, which is based on something I gleaned from some forum somewhere.
To tell it which files to use, drag the files from Explorer onto the program's file list box. To scan the files, click Scan. "Scan" will change to "Stop", but the program can only stop between files (the user interface will be frozen when processing a single large file.)
It's operation is pretty simple. It opens each file in turn as plain text and starts counting characters and digrams. Line breaks are treated as spaces except when there is already a space in front of the line break (in which case the break is ignored).
It counts all ASCII and extended characters, but not control characters. It has no support for multibyte character encodings. It only supports plain text files; if you feed it binary or marked up files (e.g. HTML), it will count a lot of stuff you probably don't want counted.
It only counts digrams with letters, spaces, apostrophes, and commas.
If you have already scanned a file or files, and you click "Scan" again, the histogram (i.e. counters) in memory are not reset. Instead, the new data is combined with the existing data. To start fresh, click "Clear Histogram & Scan" instead.
The following table of English character frequencies was obtained from about 1,415 works of fiction (375 MB uncompressed). Many of these were classics and many others were science fiction. I haven't actually looked at all these files, so perhaps some of them have data that would bias the sample (page headings repeated for each page might give bias toward the letters in "The Hobbit", for example.) I think "The Complete Works of William Shakespeare" isn't very representative of our beloved 21st century English, but it's in there anyway ;^)
The frequency counting program spits out a lot more stuff than is useful, so I've truncated the output to something manageable:
| Single characters | Digrams |
: 72327800 (18.74%)
E: 37047647 (9.60%)
T: 27083970 (7.02%)
A: 23944887 (6.21%)
O: 22536157 (5.84%)
I: 20133224 (5.22%)
N: 20088720 (5.21%)
H: 18774883 (4.87%)
S: 18415648 (4.77%)
R: 17103717 (4.43%)
D: 13580739 (3.52%)
L: 12350767 (3.20%)
U: 8682289 (2.25%)
M: 7496355 (1.94%)
C: 7248810 (1.88%)
W: 7022120 (1.82%)
G: 6396495 (1.66%)
F: 6262477 (1.62%)
Y: 6005496 (1.56%)
P: 5065887 (1.31%)
,: 4784859 (1.24%)
.: 4680323 (1.21%)
B: 4594147 (1.19%)
K: 2853307 (0.74%)
V: 2745322 (0.71%)
": 2566376 (0.67%)
': 1699273 (0.44%)
-: 1000071 (0.26%)
?: 469889 (0.12%)
X: 454572 (0.12%)
J: 448397 (0.12%)
;: 311385 (0.08%)
!: 300580 (0.08%)
Q: 275136 (0.07%)
Z: 268771 (0.07%)
:: 96752 (0.03%)
1: 63148 (0.02%)
—: 57781 (0.01%)
0: 40105 (0.01%)
): 38729 (0.01%)
*: 38475 (0.01%)
(: 38220 (0.01%)
2: 36981 (0.01%)
’: 36692 (0.01%)
`: 36256 (0.01%)
“: 31829 (0.01%)
”: 30629 (0.01%)
3: 25790 (0.01%)
9: 24985 (0.01%)
5: 21865 (0.01%)
4: 21181 (0.01%)
8: 18853 (0.00%)
7: 17124 (0.00%)
6: 17007 (0.00%)
/: 16757 (0.00%)
_: 11605 (0.00%)
[: 11568 (0.00%)
»: 11551 (0.00%)
]: 11535 (0.00%)
«: 11187 (0.00%)
=: 9899 (0.00%)
´: 8807 (0.00%)
: 5326 (0.00%)
>: 4507 (0.00%)
~: 4067 (0.00%)
<: 3995 (0.00%)
#: 3170 (0.00%)
·: 2793 (0.00%)
‘: 2760 (0.00%)
&: 2690 (0.00%)
{: 2258 (0.00%)
}: 2142 (0.00%)
•: 2055 (0.00%)
^: 1712 (0.00%)
|: 1512 (0.00%)
\: 1366 (0.00%)
@: 1354 (0.00%)
%: 1165 (0.00%)
$: 1050 (0.00%)
Ñ: 1005 (0.00%)
|
E : 11684465 (3.19%) T: 10335417 (2.82%) TH: 8723918 (2.38%) HE: 8716051 (2.38%) D : 7204154 (1.96%) A: 7120121 (1.94%) T : 6239705 (1.70%) S : 5810135 (1.58%) IN: 5352718 (1.46%) S: 5177221 (1.41%) H: 5067304 (1.38%) ER: 4775137 (1.30%) AN: 4648890 (1.27%) W: 4636835 (1.26%) , : 4346838 (1.18%) I: 4202320 (1.15%) N : 4130827 (1.13%) : 3994699 (1.09%) RE: 3955722 (1.08%) O: 3883444 (1.06%) ED: 3462768 (0.94%) OU: 3391401 (0.92%) ND: 3276462 (0.89%) R : 3214711 (0.88%) HA: 3128527 (0.85%) B: 3088955 (0.84%) ON: 3073770 (0.84%) Y : 3070758 (0.84%) AT: 3020573 (0.82%) O : 2893003 (0.79%) EN: 2873501 (0.78%) M: 2835231 (0.77%) TO: 2751509 (0.75%) NG: 2713520 (0.74%) C: 2675341 (0.73%) HI: 2548300 (0.69%) IT: 2538359 (0.69%) F: 2505880 (0.68%) OR: 2427143 (0.66%) AS: 2369544 (0.65%) AR: 2344122 (0.64%) ST: 2280787 (0.62%) IS: 2274879 (0.62%) TE: 2205337 (0.60%) F : 2134123 (0.58%) D: 2119320 (0.58%) ES: 2091622 (0.57%) LE: 2034666 (0.55%) VE: 1971014 (0.54%) G : 1927162 (0.53%) SE: 1919855 (0.52%) OF: 1915164 (0.52%) ME: 1864256 (0.51%) EA: 1857559 (0.51%) P: 1857548 (0.51%) NE: 1783875 (0.49%) L: 1777694 (0.48%) AL: 1766489 (0.48%) LL: 1725001 (0.47%) A : 1710960 (0.47%) NT: 1709239 (0.47%) WA: 1670243 (0.46%) TI: 1591791 (0.43%) RO: 1549753 (0.42%) DE: 1509243 (0.41%) N: 1489447 (0.41%) R: 1475264 (0.40%) BE: 1449462 (0.40%) L : 1441001 (0.39%) NO: 1439321 (0.39%) H : 1414260 (0.39%) LI: 1350834 (0.37%) G: 1349022 (0.37%) RI: 1334617 (0.36%) CO: 1332112 (0.36%) EL: 1325772 (0.36%) HO: 1320541 (0.36%) E: 1311237 (0.36%) AD: 1291203 (0.35%) UT: 1257568 (0.34%) |
Here's a little treat, the layout I'm planning to support in a future version of MilliKeys: the Qwerty Omelet layout! It takes the ideas of the Metropolis layout, with the two additional constraints that
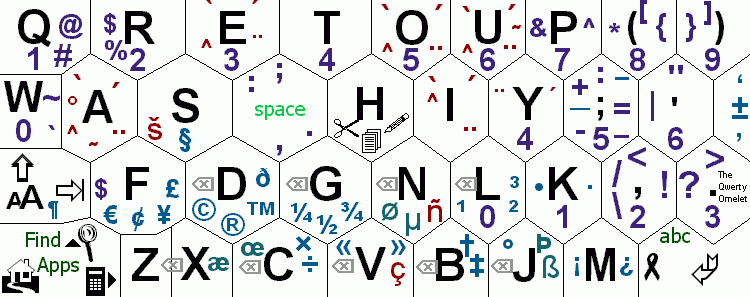
If you're used to pecking on a Qwerty keyboard, you'll appreciate that each letter in the Omelet layout is in the general vicinity of where it would be on a Qwerty keyboard. I plan to develop a near-Metropolis layout as well, but with a single-stroke-inputs-anything philosophy like the Omelet has.
See also: Layout
Does Matter
[ Home Page @ SourceForge / Geocities | SourceForge Summary | Qwertie's Page ]